Data has become a cornerstone of almost every medium-to-large business, used to derive insight and make better decisions or anticipate and respond to customer and market trends. The challenge for any business, however, is that data in and of itself cannot bring any value until it is put into an exploitable form, appropriately aligned to the needs of the business. This carries many challenges such as data quality issues giving inaccurate results or data silos making it difficult to understand how the business is performing at an enterprise rather than domain level, among others.
The data warehouse has been a staple of business intelligence for decades as one solution to this challenge. Structured data from operational systems is sourced in overnight batches and transformed to eliminate redundancy of data, standardise it, and create a “single source of truth”. Curated subsets of warehouse data can be formed into data marts, designed to serve a particular function (e.g. Sales or Finance), from which reporting and analytics can be performed. A customer that might be defined multiple times and represented in different ways across various Online Transaction Processing (OLTP) systems eventually becomes a single, definitive customer record in the warehouse.
Since the concept of “big data” was first coined in the mid-2000s to describe the huge volumes of data that were being captured by online services such as Google and Yahoo, businesses across every industry have become more aware of the vast amounts of data they collect daily. This has been accompanied by a commensurate desire to leverage this data in an intelligent way to make better decisions and enable new capabilities, and the adoption of infrastructure using the likes of Hadoop and cloud services has risen rapidly.
This adoption has seen the embracing of the “data lake” – a potentially vast repository of structured and unstructured data collected from across the business in real-time or batch processes, pooled in a central area. Telephone transcripts, web logs, video footage, measurements and financial data can all be streamed or sourced on an industrial scale and made available to analytics teams.
This is where the old and new worlds begin to clash. The data lake opens many new possibilities that a data warehouse cannot provide due to the data warehouse’s reliance on heavy, batch-based transformation of relational data: real-time streaming, scaling into the petabyte range, and presentation of unstructured data. What it cannot provide in its most basic form, however, is that conformed model – the “single source of truth” – that the data warehouse specialises in.
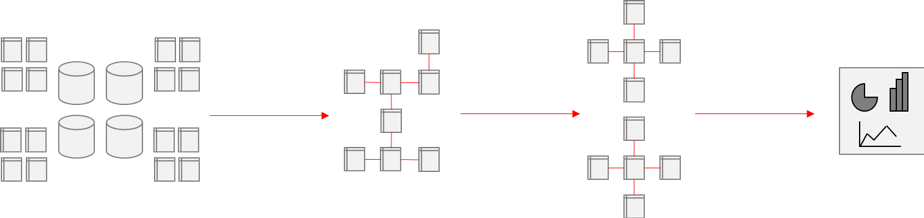
The approach commonly adopted by businesses is to use the data lake as a landing zone, accessible for data science and exploration purposes, and then a more conventional data warehouse is built from it to serve regular reporting:
However, this still carries the problem that the benefits of the data warehouse cannot be leveraged by data science or exploration. Depending on how the warehouse is implemented, it likely also means that it will still suffer the same issues of scalability, able to use potentially only a small proportion of the data in the lake at one time. Fundamentally, however, the data used by each activity is still siloed in this model, creating their own worlds from the repository of raw data in the lake.
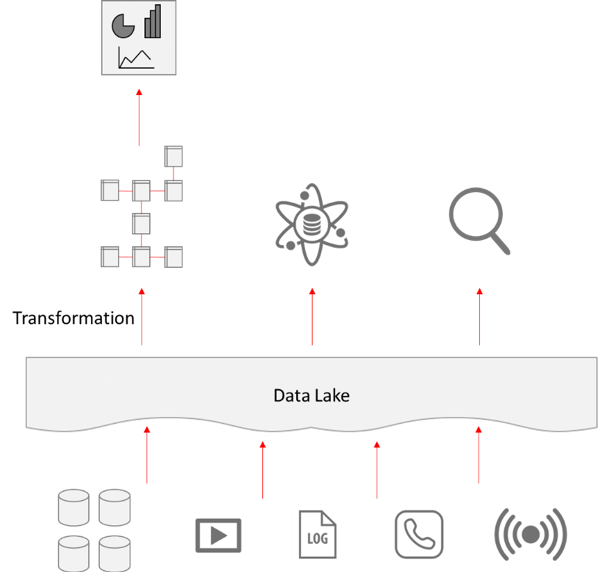
This is where the concept of the “data lakehouse” has recently come in: an attempt to leverage the best of both worlds and provide a layer of conformation and standardisation over the data lake which can be consumed by analytics, data science or exploration equally. A range of technologies such as Snowflake, AWS Redshift, Google’s BigQuery or Azure’s Data Warehouse offer dynamically-scalable compute clusters that can provide a sort of “virtual” data warehouse over the data lake, doing much of the transformation work on the fly, across large data sets:
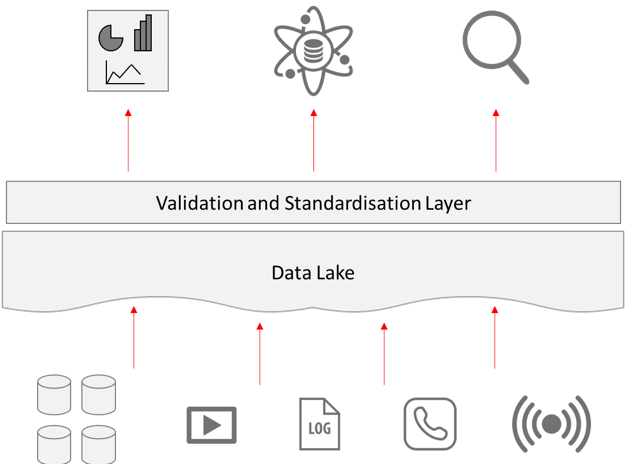
With the growing adoption of cloud infrastructure, it looks like virtualisation of infrastructure is becoming the new norm, and the data lakehouse is one example of how this is being leveraged to provide advantages that previously were thought impossible. If you think your business could benefit from this type of approach, then we would love to hear from you and advise on how you could use this to drive better value and insight.

